How to Enable Custom Robots.txt file in Blogger and fix indexing problem?

If are you facing an indexing problem and want to enable robots.txt on your Blogger website then this article is definitely helpful for you.
Here, I have explained what is a robots.txt file and why it is important for SEO. I will also tell you how you can set up a robots.txt file on your Blogger website and index your article faster.
Let’s Start.
What is a Robots.txt file?
Robots.txt file tells search engine crawlers or bots about which URLs they can access and crawl to index them on their database.
This is used mainly to avoid overloading your site with a lot of crawl requests and to save server bandwidth.
In this way, you can easily block unnecessary pages for crawling by allowing the important pages and saving server bandwidth.
The robots.txt file is a part of the robots exclusion protocol (REP), a group of web standards that regulate how robots or web crawlers crawl the web, access and index content, and serve that content up to users.
Usually, the robots.txt file is added to the root directory of the website and can easily be accessed with a URL Like this.
https://example.com/robots.txt
So, you can easily check the robots.txt file of your Blogger website by adding the robots.txt after the homepage URL as shown in the above example.
Structure of default Robots.txt file
The basic format of a robots.txt file is like this
User-agent: [user-agent name]Disallow: [URL string not to be crawled]
Here one robot’s file can contain multiple lines of user agents and directives (i.e., disallows, allows, crawl-delays, etc.).
Here each set of user-agent directives is written as a discrete set, separated by a line break.
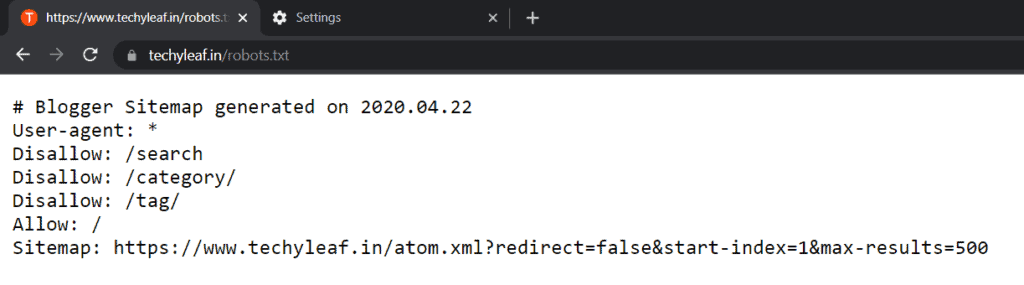
There are five common terms used in the robots.txt file.
- User-agent: It specifies the web crawler to which you’re giving crawl instructions (usually a search engine).
- Disallow: The command used to tell a user-agent not to crawl a particular URL. Only one “Disallow:” line is allowed for each URL.
- Allow: (Only applicable for Googlebot): This command tells Googlebot to access a page or subfolder even though its parent page or subfolder is disallowed.
- Crawl-delay: It specifies how many seconds a web crawler should wait before loading and crawling another page’s content. It is used to reduce the burden on the hosting server.
- Sitemap: It is Used to instruct web crawlers to crawl XML sitemap(s) associated with this URL. Note this command is only supported by Google, Ask, Bing, and Yahoo.
- Comments: Comments in a robots.txt file begin with the “#” symbol. They are ignored by web crawlers and are used for human readability and documentation. For example, # This is a comment explaining the rule.
How to enable the robots.txt file on the Blogger website?
To enable the robots.txt file in Blogger follow the below steps.

Step-1: Go to Blogger settings and search for Crawlers and indexing option.
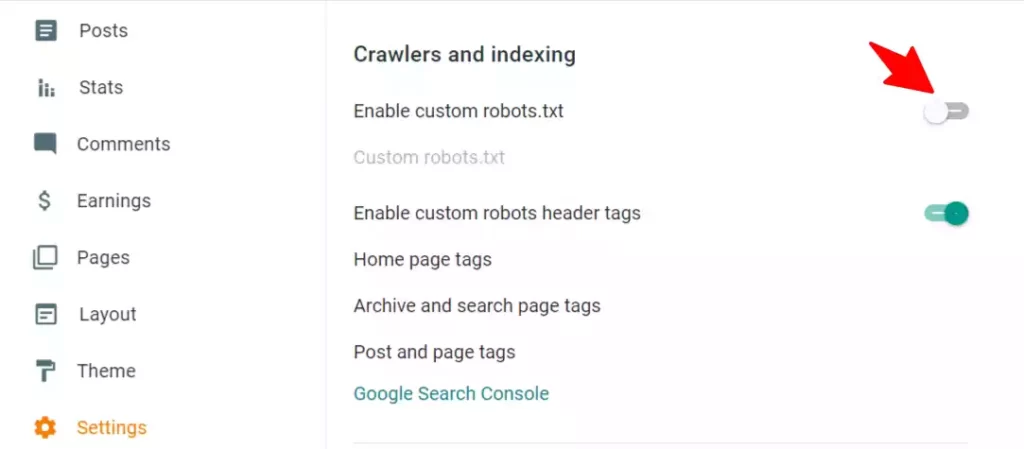
Step-2: Here turn on the “Enable custom robots.txt” option.
Step-3: Now You can Generate the custom robots.txt code for your website using Our Free Blogger Robots.txt Generator. Just Enter the Homepage URL here and Press the Generate Button.
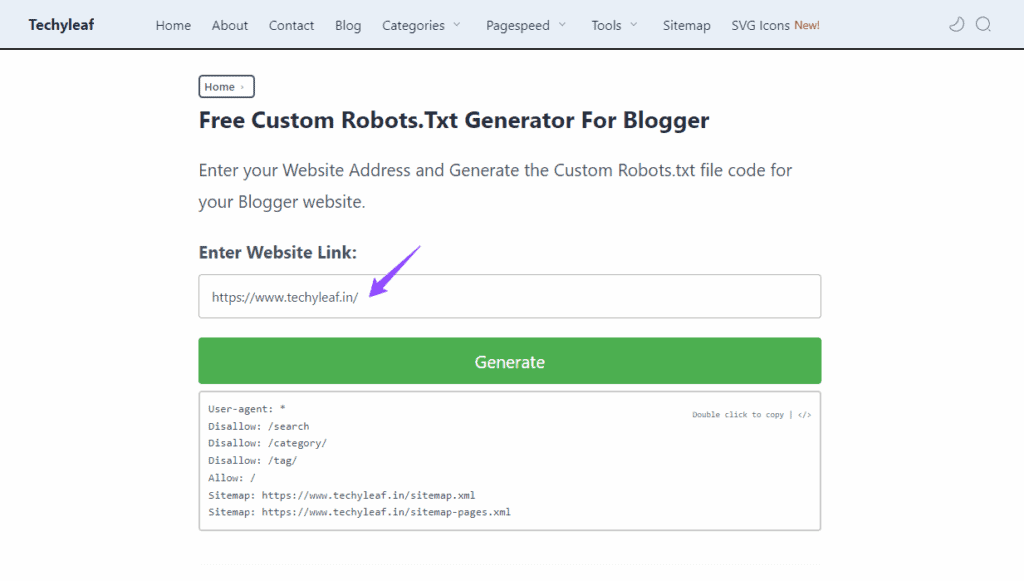
Step-4: Now save the code and the robots.txt file is added to your Blogger website.
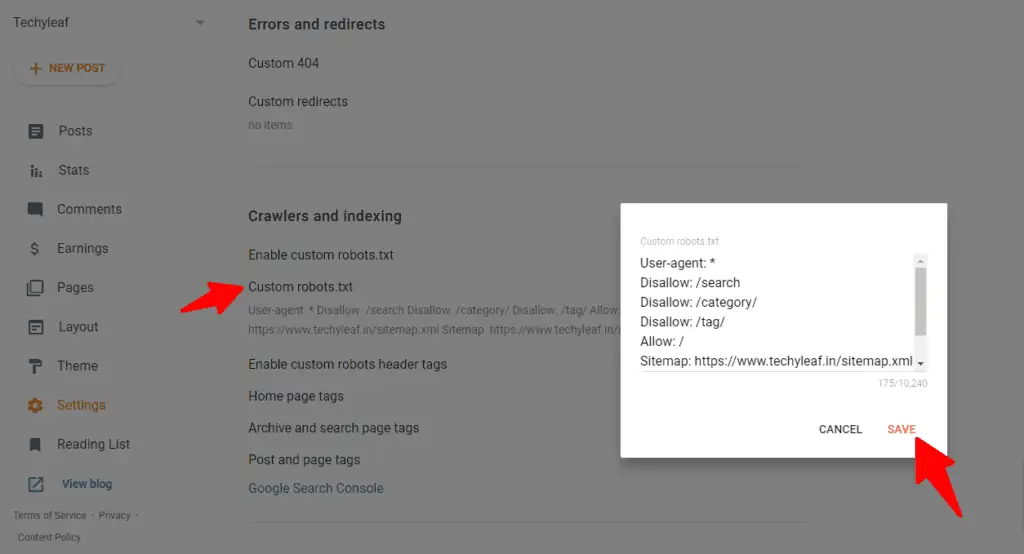
Now you can check if this is implemented properly or not by accessing the URL. (https://www.yourdomain.com/robots.txt)
Now you have set up the custom robots.txt file on your Blogger website, you can set up custom robots header tags.
Just enable this option and click on the Homepage tags, select all and noodp, and save the settings.
| Home page tags | all, noodp |
| Archive and search page tags | noindex, noodp |
| Post and page tags | all, noodp |
Why do you need robots.txt?
- Preventing duplicate content from appearing in SERPs
- It helps in blocking private sites like stagging sites
- Reduced risk of crawling unintended or test pages.
- Specifying the location of sitemap(s)
- You can prevent search engines from indexing certain files on your website (Like Premium images or PDFs, etc.)
- Clear communication with web crawlers.
- Specifying a crawl delay to prevent your servers from being overloaded when crawlers load multiple pieces of content at once
What happens if there is no robots.txt file?
If there is no robots.txt file on a website, search engine bots, and web crawlers will typically default to a set of standard behaviors. Here’s what happens if there is no robots.txt file in place:
- Crawling All Accessible Pages: Most search engine bots will crawl and index all accessible pages on your website if they don’t find the robots.txt file in the root directory. This includes both public and private content.
- Indexing Based on Links: Search engine bots rely on links to discover and crawl pages. They will follow links from one page to another, and if there are no directives to prevent crawling, they will index those pages.
- Ignoring Directives: Without a robots.txt file, there are no specific instructions for web crawlers to follow regarding which parts of your site to crawl or avoid. Therefore, they are likely to proceed with indexing based on their default behaviors.
- No Customization: You won’t have the ability to customize how search engines interact with your site. This means you may miss the opportunity to fine-tune the indexing process, protect sensitive content, or improve SEO by guiding crawlers to prioritize certain pages.
- Limited Control: You won’t be able to efficiently manage server resources or control crawl efficiency, which could lead to higher server load and increased bandwidth usage.
- Potential for Duplicate Content: Without clear directives, search engines may index duplicate content from multiple URLs, which can negatively impact SEO.
It’s also worth noting that even without a robots.txt file, other measures like page-specific meta tags, noindex attributes, and access control can be used to influence search engine behavior on individual pages.
It’s important to note that while popular web crawlers respect robots.txt instructions, not all do. If you have sensitive or confidential information on your website, it’s a good practice to use additional security measures such as authentication and access control, in addition to robots.txt.
I hope this article helps you enable the robots.txt file on your blogger website and solve indexing-related problems.
If you want to learn more about Blogging & SEO, you can follow our YouTube channel. If you found this Article Interesting, don’t forget to share it on social Media. Thank you.






Hey, thanks for the clear explanation. I have a situation where duplicate content on my 17 year old blogger site with about 2500 urls has led to 1900 urls not indexed/not visible to Google. Requesting indexing seems to lead nowhere. I use Custom robot tags for archive and search pages to noindex archive widget results. Google “Help” ALWAYS says the same boilerplate: leave that custom robots.txt sliders alone or you’ll break it. But this seems absurd. So I ended up removing my archive widget -a drastic step because the archive is useful when on the blog, if not at all for SEO. I’m not certain the widget complicated crawling and indexing, but we will see as I just removed it.
No if you implement robot text then Google not index blogger post and it shows redirect error. I advise all of them don’t implement robots
It happens when you don’t have set it correctly otherwise Custom robots.txt won’t cause redirect issues.
How can we set it right please
how to disallow comments and date from bost from crawlers
Hey man why did you made, Disallow to category and tags. Aren’t they important?
As the category and tags pages don’t show up in search results there is no need to index them in search.
It is better to block those pages to save the crawl budget of search engines bots.
Sometimes these pages also create duplicate issues.